The increasing power of computer technology does not dispense with the need to extract meaningful information out of data sets of ever growing size, and indeed typically exacerbates the complexity of this task. To tackle this general problem, two methods have emerged, at chronologically different times, that are now commonly used in the scientific community: data mining and complex network theory. Not only do complex network analysis and data mining share the same general goal, that of extracting information from complex systems to ultimately create a new compact quantifiable representation, but they also often address similar problems too. In the face of that, a surprisingly low number of researchers turn out to resort to both methodologies. One may then be tempted to conclude that these two fields are either largely redundant or totally antithetic. The starting point of this review is that this state of affairs should be put down to contingent rather than conceptual differences, and that these two fields can in fact advantageously be used in a synergistic manner. An overview of both fields is first provided, some fundamental concepts of which are illustrated. A variety of contexts in which complex network theory and data mining have been used in a synergistic manner are then presented. Contexts in which the appropriate integration of complex network metrics can lead to improved classification rates with respect to classical data mining algorithms and, conversely, contexts in which data mining can be used to tackle important issues in complex network theory applications are illustrated. Finally, ways to achieve a tighter integration between complex networks and data mining, and open lines of research are discussed.
The web browser is a program that retrieves documents from remote servers and displays them on the screen. It allows that particular resources could be requested explicitly by URI, or implicitly by following embedded hyperlinks.
The visual appearance of a web page encoded using HTML language is improved using other technologies.
The first one is the Cascading Style Sheets (CSS) that allow adding layout and style information to the web pages without complicating the original structural mark-up language.
The second one is JavaScript (now standardized as ECMAScript scripting language [1]), which is a host environment for performing client-side computations. It is embedded within HTML documents and the corresponding displayed page is the result of evaluating the JavaScript code and of applying it to the static HTML constructs.
The last one is the using of plugins[2], small extensions that are loaded by the browser and used to display some types of content that the web browser cannot display directly, such as Macromedia Flash animations and Java Applets.
[1] ECMA International is an industry association founded in 1961 and dedicated to the standardization of Information and Communication Technology (ICT) and Consumer Electronics (CE).
[2] A plug-in (also called plugin, addin, add-in, addon, add-on, snap-in, snapin) is a small software computer program that extends the capabilities of a larger program. Plugins are commonly used in web browsers to enable them to play sounds, video clips, or automatically decompressing files.
A REFERENCE ARCHITECTURE FOR WEB BROWSERS
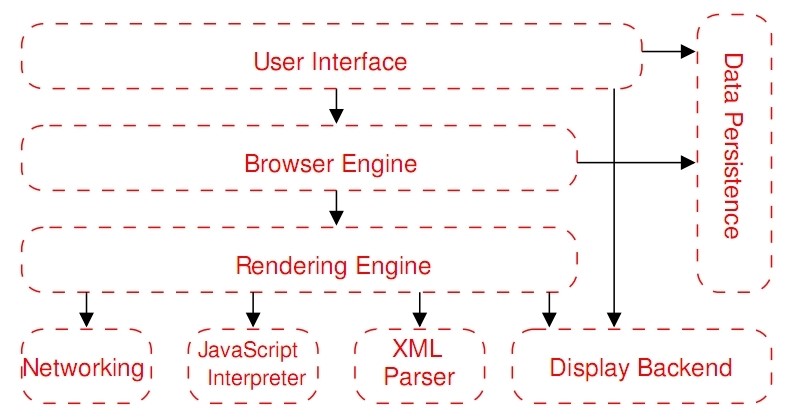
The web browser is perhaps the most widely used software application running on diverse types of operating system. For this reason, reference architecture is useful to understand how a web browser operates and what services it supplies. A schema of the reference browser architecture is shown in figure 1.
Figure1 - Web browser reference architecture
The reference schema is made up of eight major subsystems plus the dependencies between them:
1. The User Interface subsystem is the layer between the user and the Browser Engine. It provides features such as toolbars, visual page-load progress, smart download handling, preferences and printing.
2. The Browser Engine subsystem is a component that provides a high-level interface to the Rendering Engine. It loads a given URI and supports primitive browsing actions such as forward, back, and reloading. It provides hooks for viewing various aspects for browsing session such as current page load progress and JavaScript alerts. It also allows querying and manipulation of Rendering Engine settings.
3. The Rendering Engine subsystem produces a visual presentation for a given URI. It is capable of displaying HTML and Extensible Markup Language (XML) documents, optionally styled with CSS, as well as embedded content such as images. It calculates the exact page layout and may use “reflow” algorithms to incrementally adjust the position of elements on the page. This subsystem also includes the HTML parser. As an example the most popular Rendering Engines are Trident for Microsoft Internet Explorer, Gecko for Firefox, WebKit for Safari and Presto for Opera.
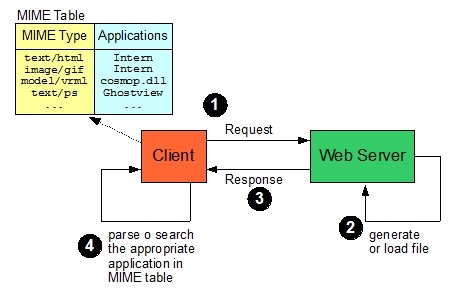
4. The Networking subsystem implements file transfer protocols such as HTTP and FTP. It translates between different character sets, and resolves MIME[3] media types for files (see figure 2). It may implement a cache of recently retrieved resources.
Figure 2 - MIME TABLE role
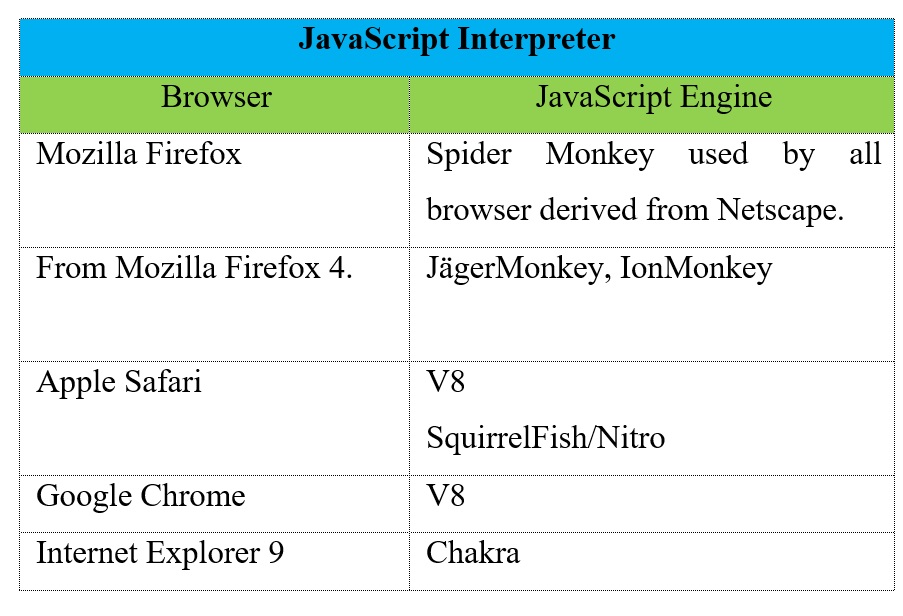
5. The JavaScript Interpreter evaluates JavaScript code which may be embedded in web pages. JavaScript is an object-oriented scripting language developed by Brendan Eich for Netscape in 1995. Certain JavaScript functionalities, such as the opening of pop-up windows, may be disabled by the Browser Engine or Rendering Engine for security purposes. In the following table we can see examples of JavaScript Interpreter.
[3] MIME was originally intended for use with e-mail attachments, in fact MIME stands for Multimedia Internet Mail Extensions. Unix systems made use of a .mailcap file, which was a table associating MIME types with application programs. Early browsers made use of this capability, now substituted by their own MIME configuration tables.
6. The XML Parser subsystem parses XML documents into a Document Object Model (DOM) tree.
7. The Display Backend subsystem provides drawing and windowing primitives, a set of user interface widgets, and a set of fonts. It may be tied closely with the operating system.
8. The Data Persistence subsystem stores various data associated with the browsing session on disk. These may be high-level data such as bookmarks or toolbars settings, or they may be low-level data such as cookies, security certificates, or caches.
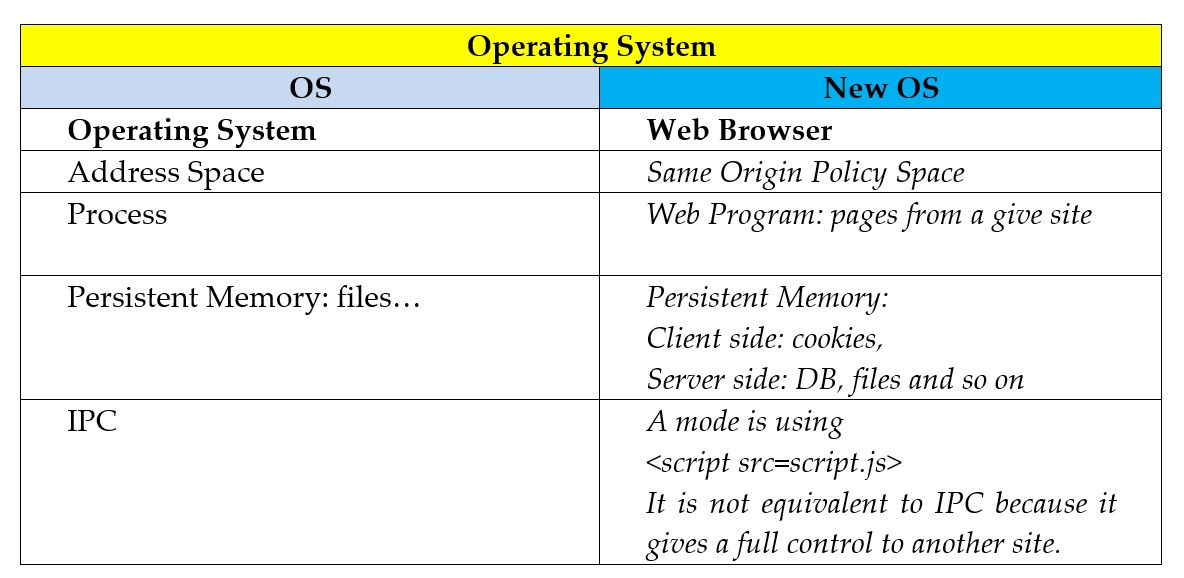
WEB BROWSER: THE NEW OS
In the following table we can see a comparison between a classical OS and the Internet Browser.
Browser Same Origin Policy (SOP)
Two pages have the same origin if the protocol, port (if one is specified), and host are the same for both pages.
Examples:
http://www.AWebSite.com:80/Page1.html
The SOP is identified by (http, AWebSite.com, 80).
https://www.AWebSite.com/Page1.html
While in this case the SOP is identified by (https, AWebSite.com, ).
The interaction between sites of different domains is regulated by the SOP. Every browser implements this policy which means:
on the client side: cookies from origin (document.domain) A are not visible to origin B; scripts from origin A cannot read or set properties for origin B using DOM interface.
on server side: SOP allows “send-only” communication to remote site.
Setting document.domain of a web page changes the origin of the page in fact this property sets or returns the domain name of the server from which the document is originated.
Some Same Origin Policy (SOP) Violations
1) Tracking users by querying user’s history file.
Attacker learns how long it took to load victim/login.html.
REFERENCES
[01] Alan Grosskurth, Michael W. Godfrey, Architecture and evolution of the modern web browser, David R. Cheriton School of Computer Science, University of Waterloo, Waterloo, 2006;
[02] Iris Lai, Jared Haines Johm, Chun-Hung, Chiu Josh Fairhead, Conceptual Architecture of Mozilla Firefox (version 2.0.0.3), SEng 422 Assignment 1 Dr. Ahmed E. Hassan, 2007;
[03] Nicchi A., Web Applications: technologies and models, Edizioni Accademiche Italiane, 2014;
[04] Charles Reis, Steven D. Gribble, Isolating Web Programs in Modern Browser Architectures, University of Washington, 2009;
[05] Stanford Advanced Computer Security Certificate Program, Browser Security Model and SOAP Violations, 2007.