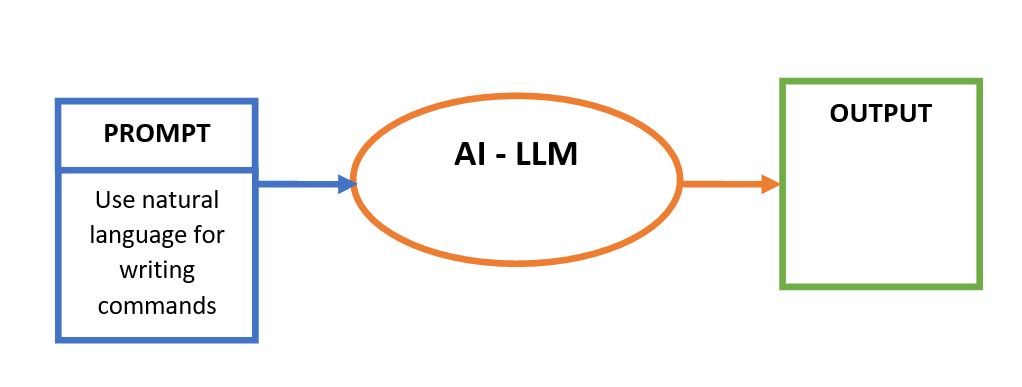
Generative AI: AN HYPER-ASSISTANT TO DRIVE INFORMED DECISION
“By leveraging AI-driven analytics, diplomats can gain deeper insights into complex geopolitical issues, identify potential area for cooperation, and optimize diplomatic strategies for greater efficacy.” [05] By Damián Tuset Varela
It is imperative for diplomats to adapt to the evolving technological landscape.
AI tools enhance the efficiency of information processing and provide strategic inside beyond traditional instruments.
AI techniques could assist and enhance decision-making processes which are often made with limited or incomplete information. Furthermore, the complex nature of diplomatic decision-making is influenced by deliberate misinformation (particularly on social media platform), data obfuscation and cultural differences.
However, the use of artificial intelligence must be seen as a tool, in which humans must always remain at the centre, to improve and make diplomacy and international relations more effective and efficient.
The following is an overview of the main tools made available by artificial intelligence applications, in particular generative intelligence.
REDUCE WASTE AND INCREASE EFFICENCY: SEVERAL AI ChatBOT PLAY ON THE FIELD
With a view to continuous improvement and increased efficiency in any context, the use of generative artificial intelligence lends itself to be a supportive and complementary tool for making informed and conscious decisions in a short time.
As evidence of the importance and effectiveness of generative artificial intelligence, many major companies are investing in this technology. Besides ChatGPT there are other chatbots. Here are the main ones:
CHATGPT (chatgpt.com): it is the most famous chatbot and virtual assistant developed by OpenAI and launched on November 30, 2022.
MICROSOFT COPILOT (bing.com/chat): it is based on the same AI technology from OpenAI. It’s free to use and you don’t need to be signed in to use the service.
GOOGLE GEMINI (gemini.google.com): it replaced Bard.
CLAUDE (claude.ai): it is one of the more sophisticated rivals of ChatGPT. Claude has a usage limit, after half a dozen of requests it stops to return available in four hours’ time.
PERPLEXITY (perplexity.ai): it only gets five searches every four hours.
META (meta.ai): it can be only used in the US.
BOOST YOUR PRODUCTIVITY AND ENHANCE YOUR POTENTIAL WITH MORE AI TOOLS
Besides ChatBOTs, there are other AI-based tools that offer specific capabilities non covered by players like ChatGPT. Here are a few examples
CANVA (canva.com): It is really good for designing posters, flyers, social media posts and the like.
NOTION (notion.so): It is a tool for creating to-do lists, taking notes o for creating personal journals. You can use it via web browser or by its mobile app.
OTTER (otter.ai): It is the best tool for transcribing meeting by video conference or in real life. Otter will listen in and transcribe the entire meeting, automatically a summary of meeting and not only. There are limits on free account. You can only record up to 300 minutes per month and up to 30 minutes in each meeting.
GAMMA (gamma.app): It is a tool to create unlimited presentations, websites, and more in seconds
LM STUDIO (lmstudio.ai): It runs an unlimited AI chatbot on your own computer rather than relying on cloud services. It is very similar to ChatGPT. It runs entirely on your device so you can even use it for sensitive tasks. It can check the Internet for up-to-date information or interacting with your files.
CHALLEGES AND OPPORTUNITIES IN THE AGE OF AI
“AI offers numerous opportunities for enhancing diplomatic efforts, fostering collaboration, and addressing global challenges in a more efficient and effective manner.” [05]
AI technologies will reshape traditional diplomatic practices.
BIBLIOGRAPHY/WEBOGRAPHY
[01] openai.com/news;
[02] theverge.com/ai;
[03] bensbites.beehiiv.com;
[04] grow.google/intl/uk;
[05] Damián Tuset Varela, Diplomacy in the Age of AI: Challenges and Opportunities, Journal of Artificial Intelligence General Science JAIGS Vol.2, Issue1, January 2024;
“ChatGPT is an artificial intelligence (AI) chatbot that uses natural language processing to create humanlike conversational dialogue. The language model can respond to questions and compose various written content, including articles, social media posts, essays, code and emails.” [04] Amanda Hetler
"People have used ChatGPT to do the following:
Code computer programs and check for bugs in code.
Compose music.
Draft emails.
Summarize articles, podcasts or presentations.
Script social media posts.
Create titles for articles.
Solve math problems.
Discover keywords for search engine optimization.
Create articles, blog posts and quizzes for websites.
Reword existing content for a different medium, such as a presentation transcript for a blog post.
Formulate product descriptions.
Play games.
Assist with job searches, including writing resumes and cover letters.
Ask trivia questions.
Describe complex topics more simply.
Write video scripts.
Research markets for products.
Generate art." [04] Amanda Hetler
By Bing Image Creator
We can’t ignore the impact on our day-to-day activities of AI tools. They make the communication between humans and machines easier and simpler.
We can quickly have new insights and information on different fields of interests. But in order to improve the quality and the accuracy of responses we have to structure and phrase of the prompt appropriately.
It’s important to remember that ChatGPT doesn’t understand and doesn’t think, it generates responses based on patterns it learned during training.
The engine of ChatGPT is based on the concept of “token”. GPT (Generative Pre-trained Transformer) model generates the tokens predicting the most probable subsequent token using complex linear algebra.
The model uses an iterative process. It generates one token at time and after generating each token, it revisits the entire sequence of generated tokes and processes them again to generate the next token.
WHAT IS PROMPT ENGINEERING
It is the art of creating precise and effective prompts to guide AI models like ChatGPT toward generating the most accurate, useful outputs. We have to bear in mind that Better Input means Better Output (BI-BO).
The prompt engineering is very important for creating better AI-powered services and obtaining useful results from AI Tools.
When you craft the prompt, it’s important to bear in mind that ChatGPT has a token limit (generally 2048 tokens), which include both the prompt and the generated response. Long prompts can limit the length of response, for this reason it is important to keep prompts concise.
Let us now analyze some techniques of prompt engineering.
INFORMATION-SEEKING PROMPTING
It is used to gather information and to answer question what and how. Examples of prompt:
What are the best restaurants in Rome?
How do I cook pizza?
CONTEXT-PROVIDING PROMPTING
The prompts provide information to the model to perform a specific task. Example:
Prompt: I am planning to celebrate the Italian Republic Day in the [COUNTRY] can you suggest some original ideas to make it more enjoyable?
COMPARATIVE PROMPTING
It is used to ask the model to compare and to evaluate different options to help the user make an appropriate decision. Example:
Prompt: What are the strengths and weaknesses of [Option A] compared to [Option B].
OPINION SEEKING PROMPTING
It is used to ask the model to get the AI’s opinion on a given topic. Example:
Prompt: What would happen if we use only public transport in Rome?.
DIRECTIONAL PROMPTING
If you ask the model for generic question, you receive generic answer. You have to define your prompt with clear instruction and precise and descriptive information.
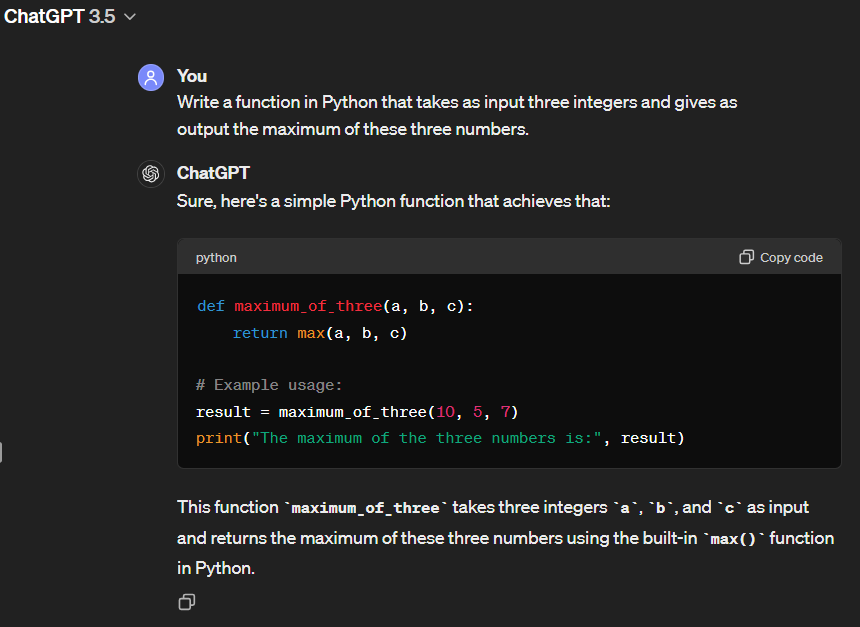
OUTPUT FORMATTING: CODE GENERATION
If you want to have a specific output or format of the output from ChatGPT, for example a program in Python or Visual Foxpro.
We try with a simple e specific request.
Prompt: Write a function in Python that takes as input three integers and gives as output the maximum of these three numbers.
ChatGPT 3.5 answer:
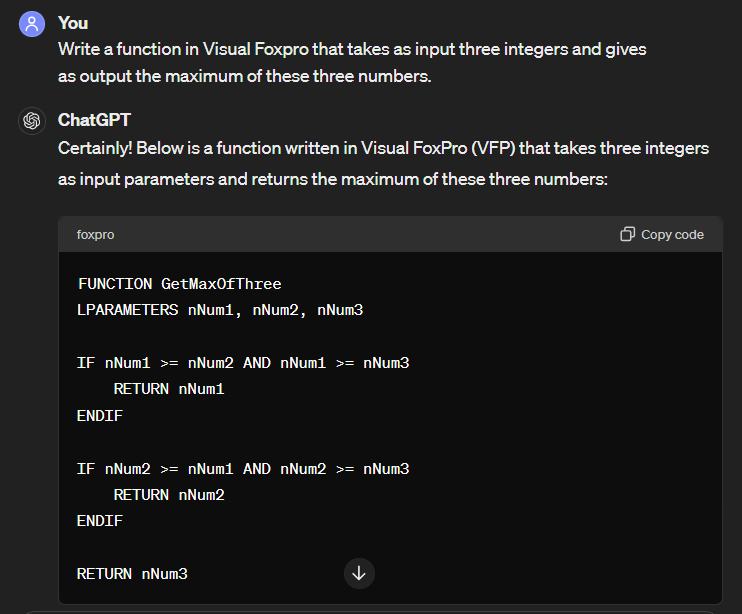
Prompt:Write a function in Visual Foxpro that takes as input three integers and gives as output the maximum of these three numbers.
Amazing, ChatGPT 3.5 answer:
VERY IMPORTANT
AI-generated code may need to be modified or tested before deploying it. It is strongly recommended to:- always modify and review the generated code to ensure it meets your specific requirements;
- use it as STARTING-POINT;- test and check the code;
- it ALWAYS NEEDS HUMAN OVERSIGHT.
ROLE PLAYING
You can also act as someone else when you interact with ChatGPT.
If you add a role to the question, you make ChatGPT change the answer and the quality and the tone of the output. In this way we got much better information. Here it is a schema to use when you build a prompt related a role playing:
WHO: you can ask ChatGPT to be what you want. You assign the role you need the model to play. A scientist, doctor, business man, chef and so on.
WHEN: you can put the character at any moment in time;
WHERE: you can put the character to a particular location or context.
WHY: you want to dialogue with the character for whatever reason, motivations or purpose you want;
WHAT: you want to dialogue with the character about what. That is the action you want the model to do.
We just need to verify the level of reliability and credibility given to this type of interaction.
Here is some practical examples.
Act as a character from a book:
Prompt: I want you to act like [character] from [book]. I want you to respond and answer like [character] using the tone, manner and vocabulary [character] would use.
Act as historical character:
Prompt: I want you to act as [historical character] to better understand the historical facts of that period.
Act as a political character:
Prompt: I want you to act as [political character] in order to ask as improving the quality of life of the people.
Act as a scientist:
Prompt: I want you to act as a scientist. You will apply your knowledge of scientific to propose useful strategies for saving the environment from pollution.
Act as a travel guide:
Prompt: I want you to act as a travel guide from Italy at the time of the Roman empire when Caesar was emperor. I will write you my location and you will suggest a place to visit near my location.
ZERO-SHOT PROMPTING
In zero-shot prompting, we use a prompt that describes the task, but it doesn't contain examples or demonstrations.
You use this prompt when you trust the model’s knowledge to provide a sufficient answer.
Prompt: Write a description of the Colosseum.
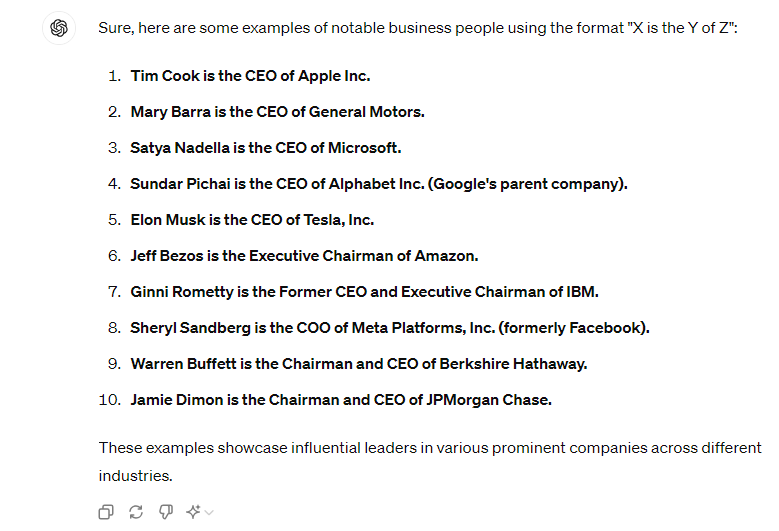
FEW SHOTS PROMPTING
It involves providing the model a few examples to guide its understanding of the desired outcome.
The example will be of:
Knowledge extracting;
And it’s formatting.
We can define the prompt like this:
Prompt:Here are some examples of each item of the list of best important business people.
X is the Y of Z
X -> [PERSON]
Y -> [POSITION/TITLE]
Z -> [COMPANY]
PUTTING ALL TOGETHER
You can also combine all these techniques:
Directional prompting;
Output formatting;
Role based prompting;
Few shots prompting.
CHAIN OF THOUGHT (CoT) PROMPTING
This technique encourages the model to break down complex tasks into smaller intermediate steps before arriving to conclusion. It improves the multi-step reasoning abilities of large language models (LLMs) and is helpful for complex problems that would be difficult or impossible to solve in a single step.
There are also variants of CoT prompting, such as "Tree-of-Thought" and "Graph-of-Thought", which were inspired by the success of CoT prompting.
IN STYLE PROMPTING
You can ask the model for the style of the output:
Writing as another author;
As emotional state;
In enthusiastic tone;
Writing something in a sad state;
Rewriting the following email in my style of writing;
Rewriting the following email in the style of xy;
STRUCTURING YOUR DATA & USING TABLES
You can ask the model to extract information in the way is useful. You can ask to extract information from the example and structure it into markdown table or a specific format.
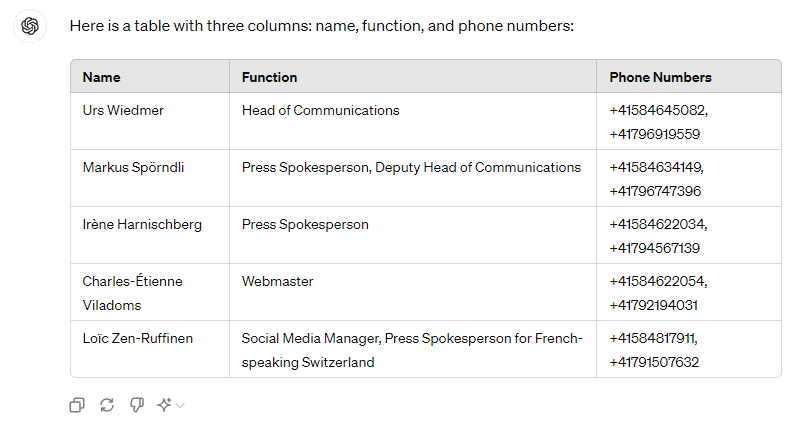
Prompt: Generate a table of three column: name, function, phone numbers from the text.
Text: “Urs Wiedmer Head of Communications +41584645082 +41796919559 Markus Spörndli Press spokesperson Deputy Head of Communications +41584634149 +41796747396 Irène Harnischberg Press spokesperson +41584622034 +41794567139 Charles-Étienne Viladoms Webmaster +41584622054 +41792194031 Loïc Zen-Ruffinen Social Media Manager Press spokesperson for French-speaking Switzerland +41584817911 +41791507632"
You can give to the model a big chunk of text and ask to summarize it.
For example, You can prompt:
Prompt: You are summarization bot any text that I provide to you summarize it, and create a title from it.
But a more effective technique could be:
Prompt:summarize the text below as a bullet point list of the the most import points.
Text: “ … “
If you need to generate a brief overview of a scientific paper don’t use generic instruction like “summarize the scientific paper” instead you should be more specific.
Prompt:generate a brief (approx. 300 words), of the following scientific paper. The summary should be understandable and clear especially to someone with no scientific background.
Paper: “ … “
TEXT CLASSIFICATION
You can use the model:
As SPAM DETECTOR in the mail;
To perform SENTIMENT ANALYSIS for brands and so on.
You can prompt:
You are a sentiment analysis bot. Classify any text that I provide into three classes:
NEGATIVE
POSITIVE
NEUTRAL
CONSIDERATIONS ON AI GENERATED RESPONSES
The AI-generated responses aren’t always correct. You have always to verify that the AI-generated output is accurate and up-to-date. This is important of you want to make an informed decision based on the response generated.
In any case, it is a good practice to have some idea of what you are asking for in order to properly evaluate the answer obtained from AI.
LLMs are neural networks that can process and generate natural language text.
Midjourney Bot APP — Today at 19:22 LLMs are neural networks that can process and generate natural language text. - Image #1 @Ahdpea8
TRAINING PHASE
They are trained on a dataset of billions of sentences using unsupervised learning techniques. In the training process LLMs learn what is the most likely word to came next to the previous one based on huge amount of data.
INPUT BY USER
LLMs accept as input a text prompt by a user and in relation with it generate in output text, word by word (token by token).
GENERATION OF THE OUTPUT
The generation process consists in predicting the next word on the base of previously generated words. LLMs are trained in doing this without any consciousness which is a prerogative of the human mind.
Building a Simple Large Language Model
In this example we use as data the dystopian novel “Nineteen Eighty-Four – 1984” by English writer George Orwell, published on 1949.
Using the text of the novel as a data source, the following tables were produced. I show only a part of them:
Word/Token
Occurrences
the
6249
of
3309
a
2482
and
2326
to
2236
was
2213
He
1959
It
1864
in
1759
that
1457
had
1311
his
1079
you
1011
not
827
with
771
as
672
At
654
they
642
for
615
IS
614
but
611
be
608
on
604
were
583
there
559
Winston
526
him
512
i
495
which
443
s
439
one
426
or
424
…
…
Word/Token
Word Next
Score
Probability
of
the
743
0,01139
It
was
589
0,00903
in
the
574
0,00880
He
had
355
0,00544
he
was
273
0,00418
on
the
230
0,00352
was
a
225
0,00345
there
was
223
0,00342
to
the
212
0,00325
O
Brien
205
0,00314
to
be
203
0,00311
and
the
203
0,00311
had
been
202
0,00310
the
party
195
0,00299
at
the
183
0,00280
that
he
167
0,00256
from
the
161
0,00247
with
a
158
0,00242
did
not
148
0,00227
that
the
147
0,00225
of
a
145
0,00222
of
his
145
0,00222
out
of
142
0,00218
was
not
130
0,00199
with
the
127
0,00195
he
could
124
0,00190
it
is
124
0,00190
in
his
123
0,00188
in
a
122
0,00187
They
were
122
0,00187
seemed
to
115
0,00176
was
the
110
0,00169
could
not
109
0,00167
he
said
109
0,00167
the
same
103
0,00158
for
the
101
0,00155
by
the
95
0,00146
for
a
92
0,00141
into
the
92
0,00141
she
had
87
0,00133
as
though
82
0,00126
they
had
80
0,00123
that
it
80
0,00123
have
been
79
0,00121
and
a
78
0,00120
it
had
77
0,00118
The
other
76
0,00116
of
them
76
0,00116
to
him
75
0,00115
the
telescreen
75
0,00115
BIG
BROTHER
73
0,00112
…
…
…
…
This is a simple diagram to understand how the text is generated word by word.
For example, if I start with BIG, LLM will probably generate BROTHER, and continuing we can produce this sentence:
BIG
BROTHER
was
a
sort
of
the
thought
…
Probability
0,00112
0,0005
0,00345
0,00095
0,00104
0,00023
0,00087
ChatGPT is a LLM
By using “prompt” mechanism you can ask ChatGPT for what you want using the natural language.
But how ChatGPT “UNDERSTAND” text inserted by the user?
The text is transformed and each word represented by a code that computer can processed.
A way to represent individual words is Word2Vec technique in natural language processing (NLP), in which each word is represented by a vector (a set of numbers). This helped a computer to assign a meaning to the word.
Word2Vec stands for “words as vectors”. It means expressing each word in your text corpus in n-dimensional space. The word’s weight in each dimension defines it for the model.
The meaning of the words is based on the context defined by its neighboring words where they are associated.
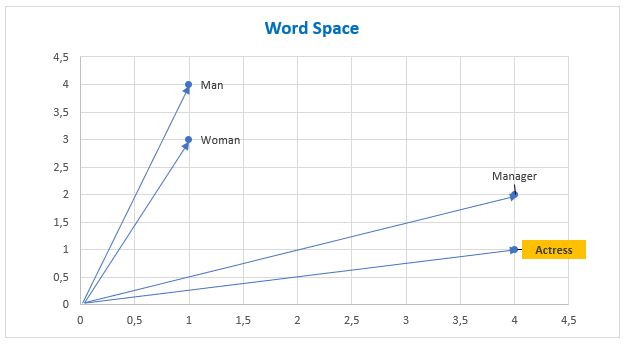
A simple example of word representation using the Word2Vec approach in two-dimensional space.
Man = [1,4]
Woman = [1,3]
Manager = [4,2]
Actress = [4,1]
Manager
-
Man
+
Woman
=
Actress
[4,2]
[1,4]
[1,3]
[4,1]
In the following picture we have the graphic representation.
This is what happens when you sent some prompt to ChatGPT.
The text is converted and split in tokens;
[10,10], [10,31], [10,15], [14,44], [8,5], …
(you, are , an, ICT, specialist, with, a, lot, of, experience)
An algorithm (like ChatGPT) makes some prediction and output text word by word.
[10,10],…
(you,can,have, an, important, and, well-paid, job)
ChatGPT and PROMPT ENGINEERING
Let us now analyze some techniques to better exploit the potential of ChatGPT.
DIRECTIONAL PROMPTING
If you submit the same question to ChatGPT many times, you will likely receive different answers.
How can you use directional prompting in order to get more precise answer?
You have to give more information and to be more descriptive when you define a prompt. You have to give clear instruction. This will help the model to understand of what you want. If you ask for generic question, you receive generic answer.
Generic question:
More specific question:
More contextual and specific question:
OUTPUT FORMATTING
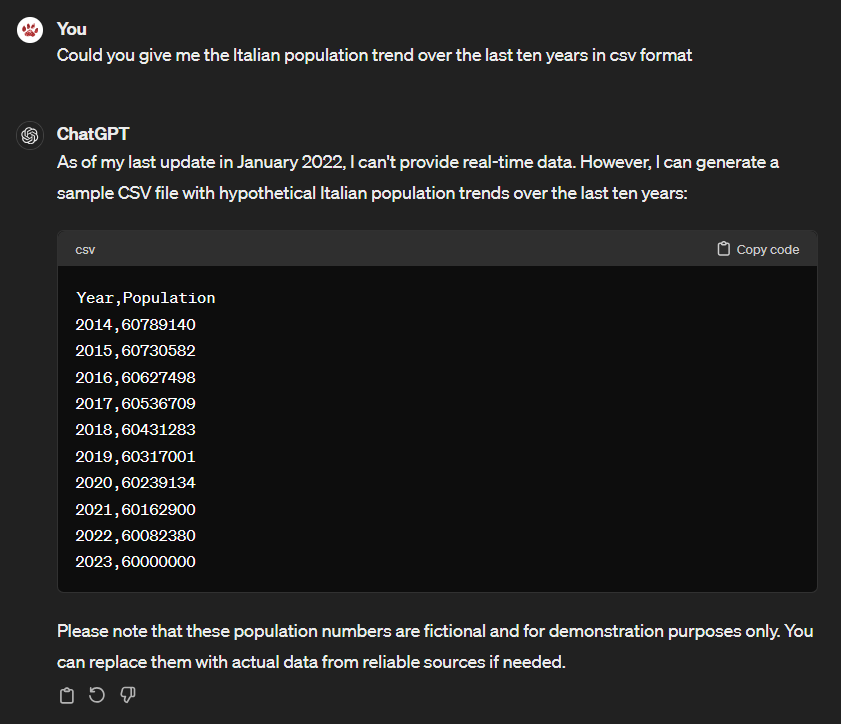
If you want to have a specific output or format of the output from ChatGPT, for example CSV (Comma Separated Values), Microsoft Excel, Microsoft Word or simply txt or maybe code as well, you have to specify as in the following examples.
We want statistical data in CSV format:
BIBLIOGRAPHY/WEBOGRAPHY
[01] openai.com;
[02] KENNETH WARD CHURCH, Emerging Trends Word2Vec, IBM 2016;