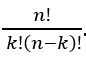Continuous improvements of ICT technologies give exponential accelerations to all areas in all private and public sectors.
The gold for a private or public manager/diplomat is to keep up with the changes caused by new technologies by using a soft skill approach.
Diplomats should be efficient and flexible and should possess a high ability to adapt to the fast changes of the world.
In this scenario, we assist to an improvement in the development of open source intelligence (OSINT) tools and techniques.
OSINT is the act of gathering intelligence through exploiting all the information that is publicly available.
Wikipedia defines OSINT as “Open-source intelligence (OSINT) is a multi-factor (qualitative, quantitative) methodology for collecting, analyzing and making decisions about data accessible in publicly available sources to be used in an intelligence context.” [02]
The amount of publicly structured data, semi-structured data e unstructured data is huge. We need skill for analyzing them in order to make correlations, extracting information and then knowledge, which could be used for predictions or making policies and strategies.
Many governmental and non-governmental structures use OSINT services: government organizations, Economist Intelligence Unit, BBC, who do investigative journalism, many private corporations for commercial advantages and do son.
Why not use OSINT services in the diplomatic field? Diplomacy could gain advantages on knowledge obtained by OSINT services putting into operation strategies and policies in a predictive way especially in the economic sector.
OSINT smart prediction machine
The scheme of work of OSNT is simple:
Gathering and collecting all type of public data you can in any form;
Organize them in a way you can manipulate;
Analyze them and find hidden correlations;
Generate information and statistical projections;
Produce useful knowledge.
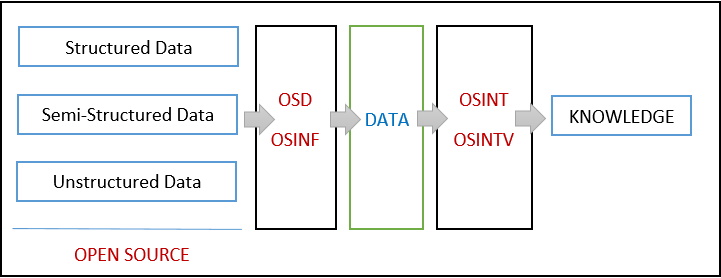
Here it is the machine model:
where:
Open Source Data (OSD): datasets, survey data, metadata, audio or video recordings and so on;
Open Source Information (OSINF): books on a specific subject, articles, interviews and so on;
Open Source Intelligence (OSINT): all information discovered, it is the output of open source material processing;
Validated OSINT (OSINT-V): OSINT confirmed/verified using highly reputable source.
REFERENCES
[01] Clima, energia e digitalizzazione: le sfide per la diplomazia economica 4.0 - Intervista a Marco Alberti a cura di Alessandro Strozzi: Pandora Rivista N.3/2020;
When we ask the visualization of a web page in the browser, it could shows you:
Warning: Unresponsive script" prompt that says "A script on this page may be busy, or it may have stopped responding. You can stop the script now, or you can continue to see if the script will complete."
It means that a script takes too long to run and the browser doesn’t accept it.
A consequence of it is that the user interaction with the browser and web page is stopped.
The browser UI and JavaScript code share a single processing thread. Every event is added to a single queue. When the browser becomes idle, it retrieves the next event on the queue and executes it.
In reality, browsers starts a new OS process for every tab. However, there is still a single event queue per viewed page and only one task can be completed at a time. This is necessary for rendering the web page and for the user interaction with the web page in the browser.
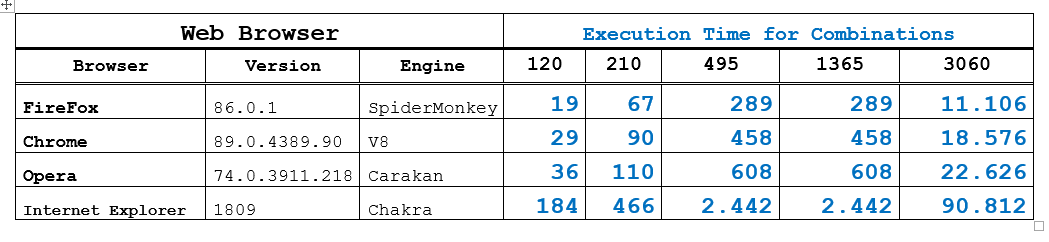
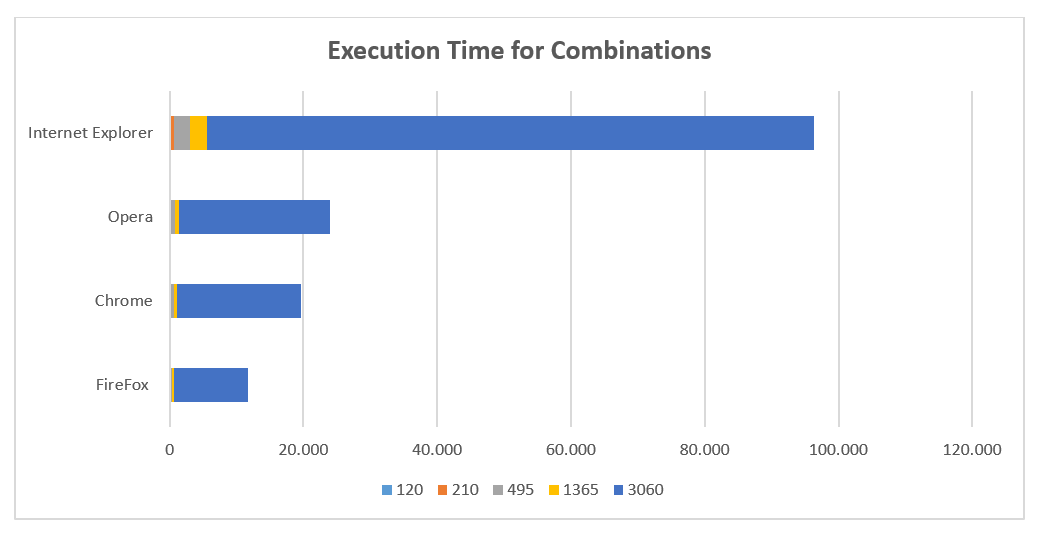
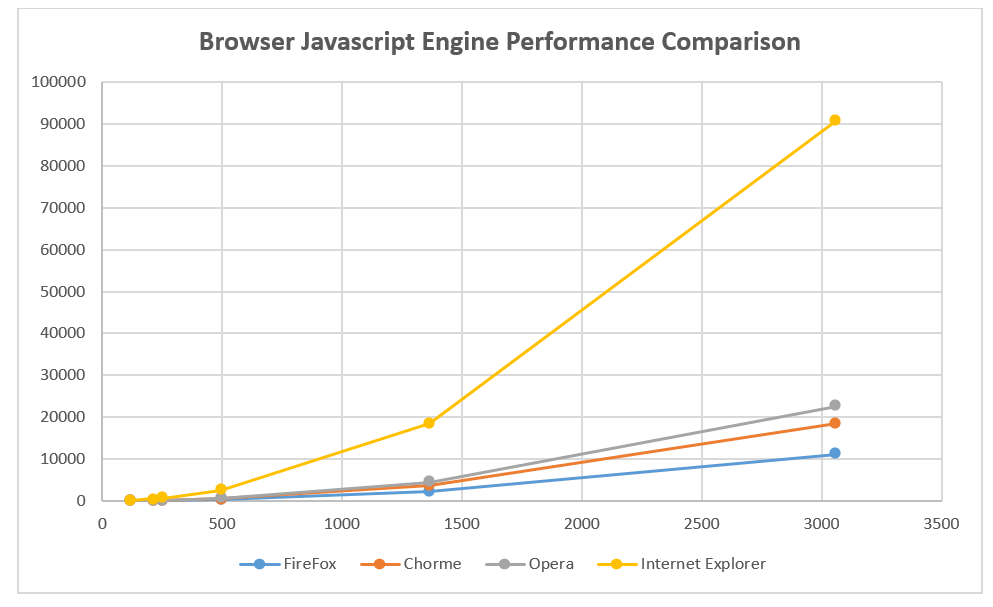
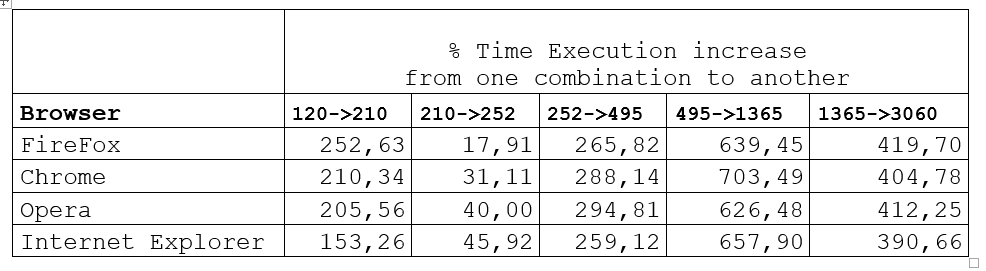
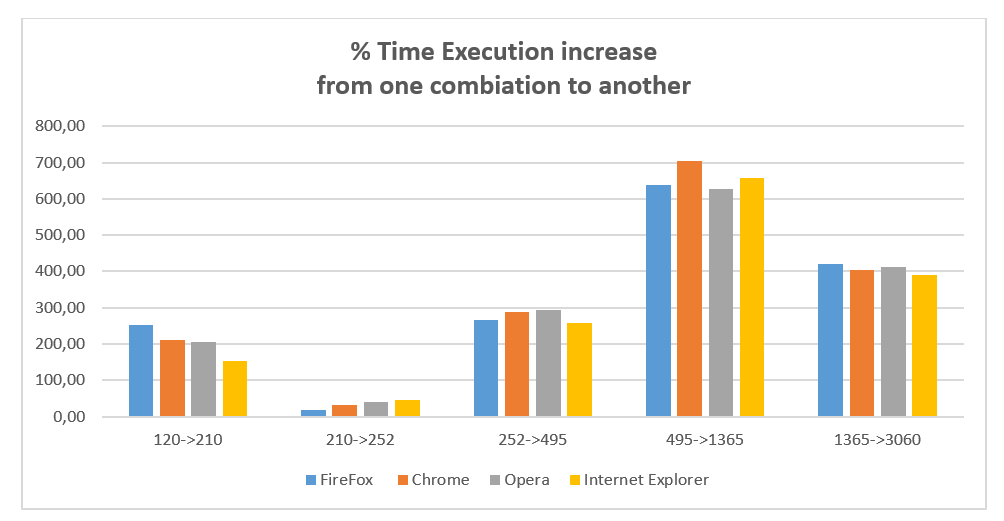
To test the speed and limit of web browser in the execution of the JavaScript code we are going to use a heavy processing algorithm for generation of combinations without repetitions.
DONALD KNUTH’S ALGORITHM FOR GENERATION OF COMBINATIONS WITHOUT REPETITIONS
The number of combinations of n things, taken k at a time are exactly:
We can think these n things as an ordered collection of objects and we can use binary notation to discover combinations.
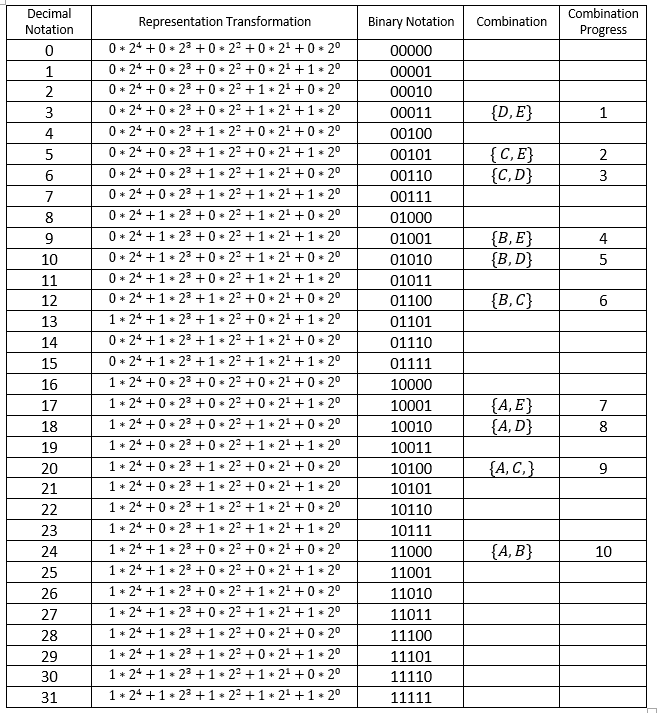
For example, we take a set of five letter: {A,B,C,D,E} and we want to list the combinations of 2 letter from this set without repetitions. Using the formula above the number of combinations is 10.
We consider this set as an ordered set: A<B<C<D<E and we use the binary notation to represent it where
0 means the letter is not in the combination and 1 means the letter is in the combination.
We know that the number of all subsets is = 32 > 5, while we have to select of these subsets only those that have a number of elements equal to 2.
Considering the set as an ordered set {A,B,C,D,E} and using the binary notation, the list of all subsets of this set are:
Only good binary representations are used to generate good combinations.
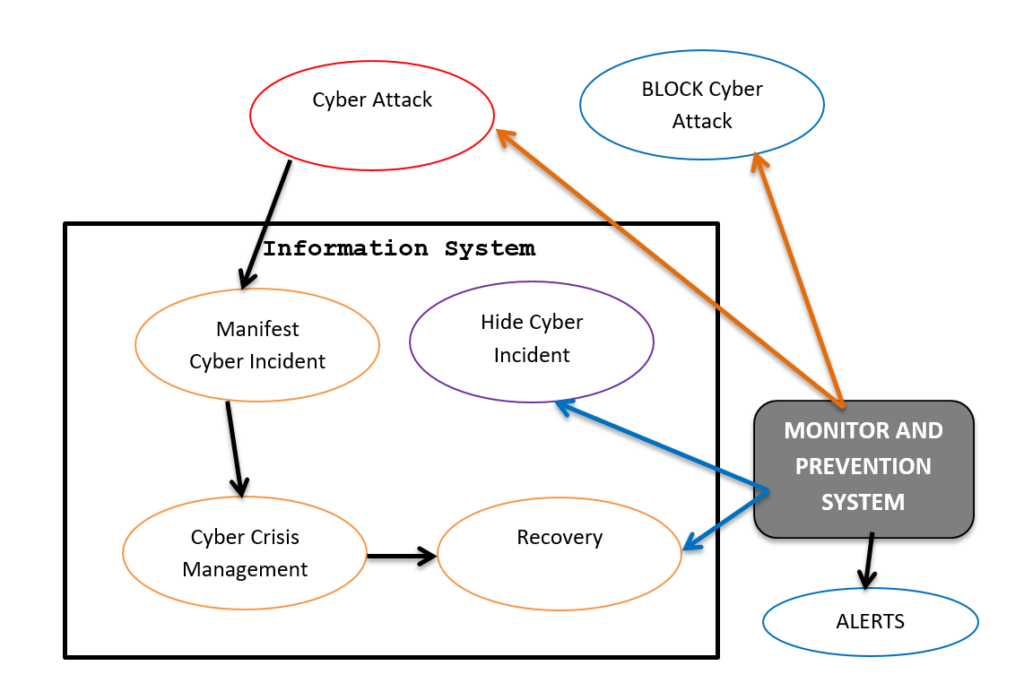
Just some personal notes and thoughts about a different approach to cybersecurity defense system.
In the cyberspace the scenario in which every day an Information System
(IS) lives is more or less this one:
It could have a cyberattack by bad guys/organizations;
If the cyberattack has success the Information System
could be compromised in a hide or manifest way;
If we realize that the Information System is
compromised, we start the security crisis management;
After the incident management we analyze what happened
and try to harden more the defense system.
Cybersecurity attacks
The cyberspace is not a secure world you can be the target of many types
of attacks, for example we can have:
Denial-of-service
(DoS) and distributed denial-of-service (DDoS) attacks;
Man-in-the-middle
(MitM) attack;
Drive-by
attack;
Password
attack;
SQL
injection attack;
Cross-site
scripting (XSS) attack;
Eavesdropping
attack;
Birthday
attack;
Malware
attack;
Phishing
and spear phishing attacks;
And so on.
Cybersecurity HIDE incident
If the attack has been success but we don’t have any idea about what’s going on. This is the worse situation in which we can be. No one alerts us about it. The question is: where is my high defense system? In this situation only a very smart and good monitor system can detect that my system is compromised and where is the problem.
Cybersecurity manifest incident
If the attack has been success and we realize that our information
system is compromised we can only face and manage the incident, which could be:
A Data
leakage of any type: mails, photos, credit card data, sensitive personal data
and so on;
A Crashed
web sites;
A Breached
networks;
A Denials
of service;
A Hacked
devices;
A Organizations’
decrease of reputation by leakage of information or successful cyberattack with
huge economic loss;
A Personal
loss of reputation;
And so on
Post-incident analysis
In this phase it occurs to assess the causes and to analyze the company’s crisis management capabilities in order to eliminate deficiencies in the cyber defense system to improve its resilience.
First Line of defense model
But what is the first line of defense model? As we can see in schema is
the monitor system. It is very
important and its role is crucial and fundamental. Every slice of second it has
to tell us:
First of
all I’m good I’m working well, I’m not compromised;
the IS is
not under attack;
the IS is
working according the specifications and it is not compromised.
or:
The IS is
under attack but it is not compromised and I immediately inform the emergency
team to stop it.
The system
is compromised I didn’t detect the intrusion but I realize that the attack had
success we need to recovery. This is the worse situation but the monitor immediately
alert system advises about it in order to contain the damage.
Or:
Anyone of the above sentence is a fake news. This means the monitoring
system does work well. In this case we are in the very bad situation that we
need to minimize by increasing and improving the capabilities and intelligence of
control and auditing every days of monitor system.
But what does the monitor mean?
Monitor means to check, to verify that everything is working according
the rules and specifications.
The monitoring activity should be at different levels:
Network
level that is packet analysis and so on;
Operating
system level;
Application
Level;
User behavior;
and it should analyze, combine
and correlate events at different levels for a better control of IS.
I think we can have
the last defense technology but without a very smart monitor working 24/7 on
the information system we don’t have a good cyber security system.